前不久,在集团内部做了一个 CR 系统,可以从设计稿上截图识别某个组件并给出代码。
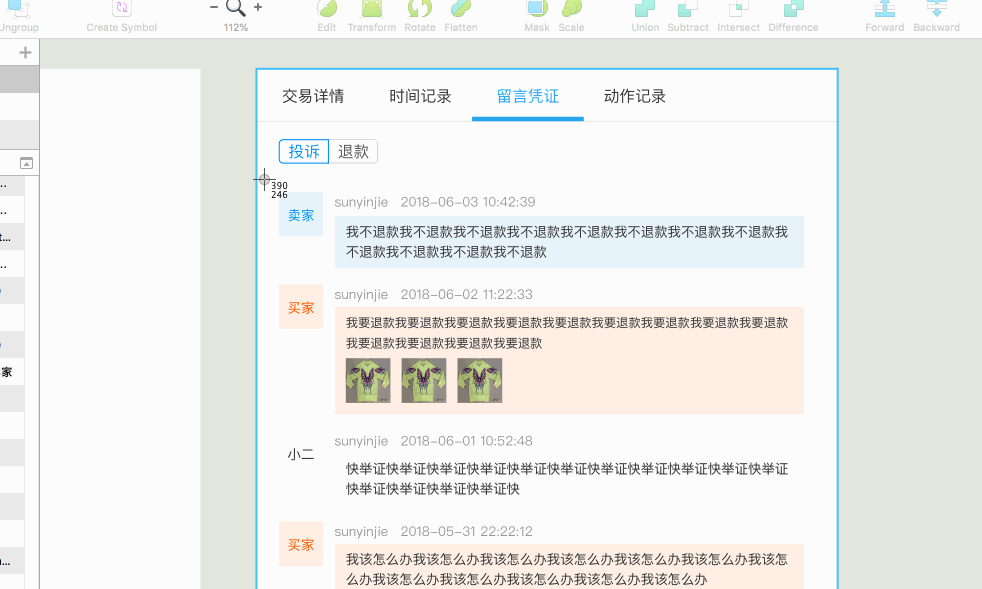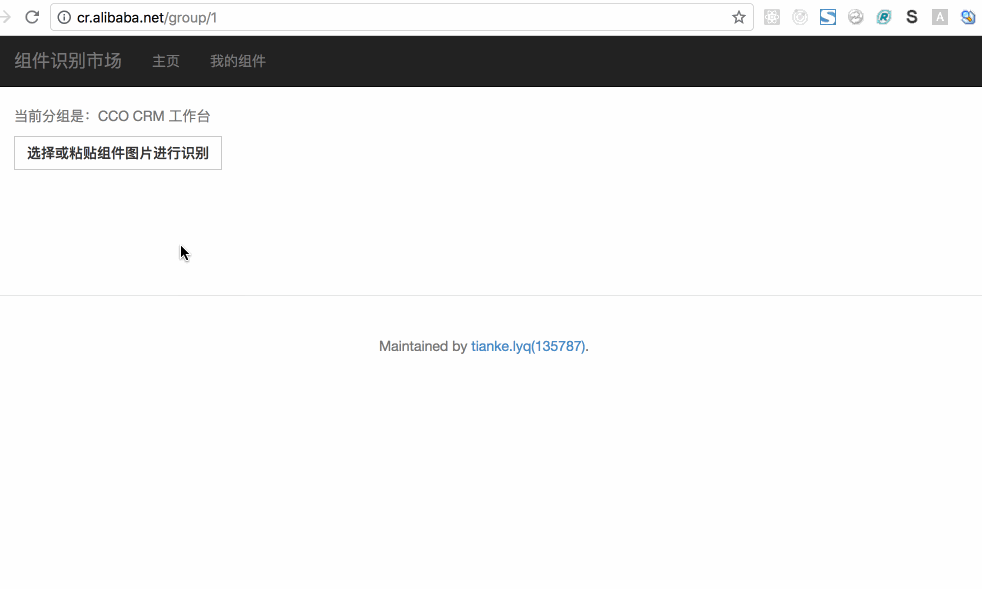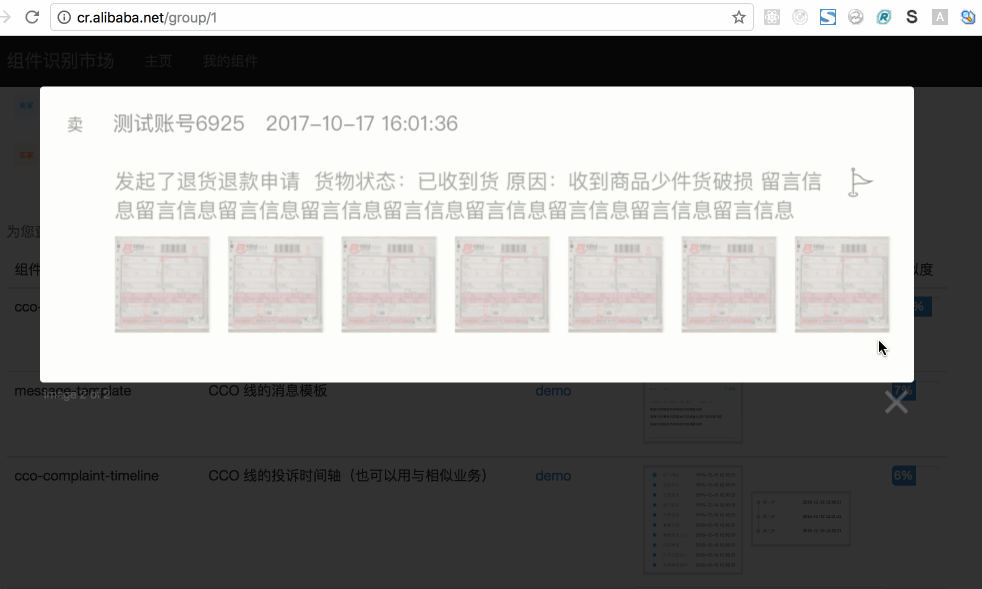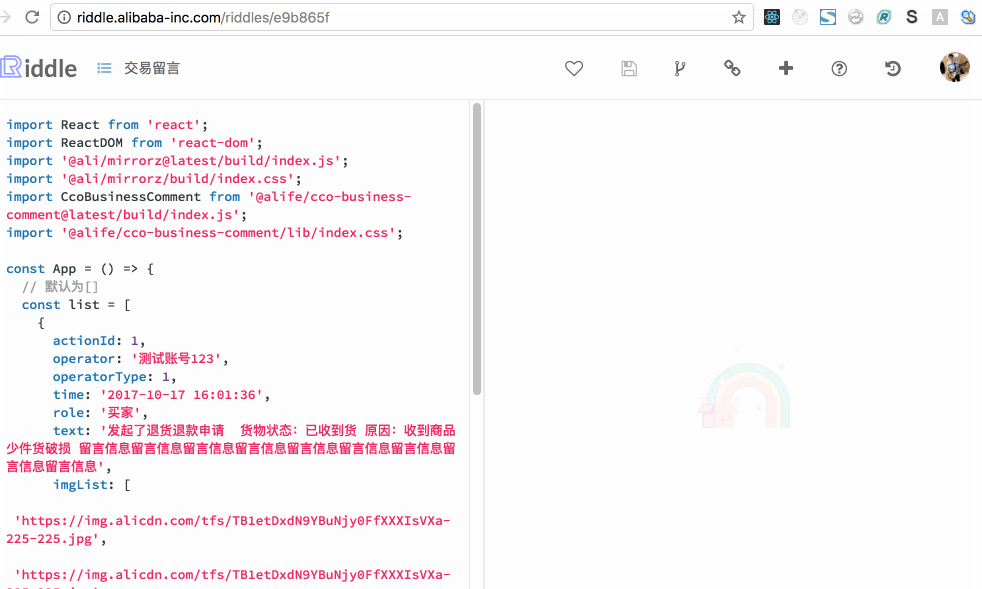
但是,我不想只是识别单个组件,最好能识别整张设计稿的多个组件。于是,花了两三天进行了这项技术的探索调研,并将过程记录下来。
技术选型
二值化处理
识别多个组件的本质是定位,我首先想到的是像车牌定位,或者跳一跳外挂那样的利用颜色,进行二值化等处理进行识别,但设计稿中的组件并没有非常明显的边界,这种方法显然是不可行的。

TensorFlow Object Detection API
后来发现了谷歌开放的 TensorFlow Object Detection API,顿时看到了希望。TensorFlow Object Detection API 可以创建一个精确的机器学习模型,该模型能够在单张图片中对多个物体进行定位、分类。看了几张效果图,认为应该有戏:


机器选择
TensorFlow 可以在各个系统上跑,甚至可以在浏览器里运行和 retrain。但是如果要有更好的速度,最好选择可以用 GPU 的系统,由于 OSX 系统的在显卡方面的封闭性,TensorFlow 不支持在 OSX 上跑 GPU 版本,所以剩下的选择是:
- WIndows 或者 Linux 系统的电脑
- 谷歌云
- 集团的 PAI 平台
- 其他云平台
由于云平台对我来说会增加一些熟悉成本,而我目前又只是急于知道多组件识别的可行性,所以就借了部门实习生的台式机来训练,正好这位实习生不习惯用 Windows 系统,自己带了 Macbook,所以就很爽快地借给我了。不过,不得不说集团给实习同学配置的电脑配置确实很基础,8g内存,Nvidia GeForce GT 730 的显卡,再差一点就跑不动 GPU 版本的 Tensorflow 了。
模型选择
TensorFlow Object Detection API 提供了一些现成的模型来让你直接用或者重新训练,它们的区别在速度和精确度上。因为我的台式机配置较低,所以选择了速度较快,精度较低的模型(ssd_mobilenet_v1_coco)来重新训练。
训练图片选择
我们要进行的是整张设计稿的识别,所以最初我用的训练图片是整张设计稿,但训练下来,发现根本识别不出来什么。
思考了一下,发现是因为:
- 图片尺寸太大
- 而上步选择的模型只支持小尺寸的图片(毕竟那个模型是给移动端用的)
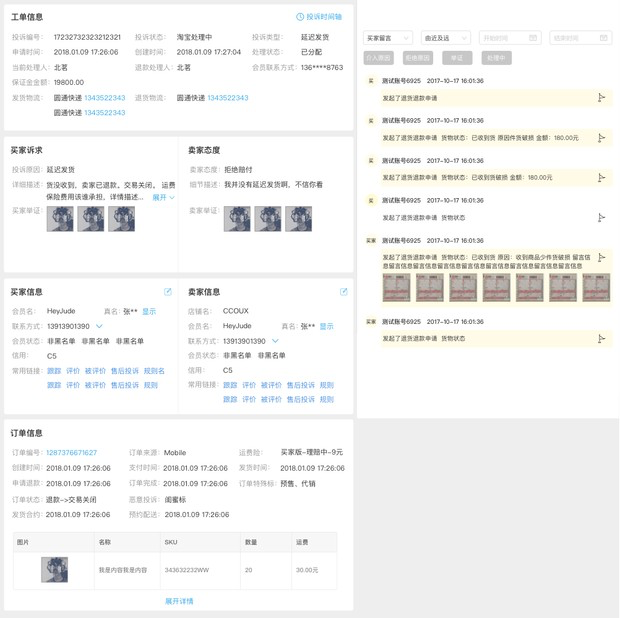
于是我打算缩小图片尺寸,换成了表单项的识别,即在一个表单上识别出输入框、下拉框、文本框等。将尺寸缩小后,我在那台低配的台式机上训练了半个小时(没跑完),最终识别效果图如下:
至少证明是可行的了。但是还有一些表单项没有识别出来,所以我继续缩小训练图片的尺寸,将七个表单项的识别换成三个,训练了一个小时(也是没跑完),测试了一下,可以全部识别出来了:

最终结论
首先,整张设计稿的多组件识别是可行的,但是需要几个前提条件:
有充足的 GPU 资源:如果你像我一样只有一台低配机器,那么精度高的模型,你跑都跑不动,显卡内存直接占满,程序崩溃。
有充足的设计稿素材:由于只是验证可行性,所以我只训练了十张图片,但是要达到很好的效果,至少得有一百张图片来训练,所以你得有足够多的设计稿素材。
有充足的人手和时间:训练 Object Detection 模型不像 Image Classification 那样简单,需要你手动标注位置,生成 xml 文件来给机器学习,这个工作非常无聊繁琐,所以如果要做,必须有足够多的人和时间。
暂时就写这么多了,笔者研究较浅,请多多批评!