今天,我们要讲的是如何在端对端测试中模拟 HTTP 请求。这个技术在复杂系统中非常实用,让我们一睹为快。注意,本文是给有一定端对端测试经验的测试工程师或前端工程师看的,如果你对端对端测试一无所知,请先阅读我之前写的关于端对端测试的文章 。
复杂系统中的端对端测试的问题 最近想在公司内部一个非常复杂的后台系统中添加端对端测试。这个系统拥有很多页面,每个页面都有很多功能,在这些功能中,不仅涉及许多数据库操作,还包含一些对用户来说不可控的外部数据来源。给这样的系统添加端对端测试,我的内心是崩溃的,因为如果完全模拟用户操作,我会面临很多问题:
把数据库搞得一团糟:添加很多乱数据,不小心删除一些关键数据(试想这些数据万一是巨额钱款呢?!) 因为一些不可控的外部数据,我的测试脚本面对的场景可能每次都不一样,可我的脚本却只有一份,也许今天脚本能跑,明天脚本就出错了。 在真实场景下,一些边界情况的逻辑往往测试不到,比如空数据,错误数据的处理等。 是否应该简化或放弃端对端测试? 面对这些问题,我当时冒出了放弃的想法,我咨询了一些同事,他们有的人让我评估可行性、必要性,有的人说让端对端测试测一些简单的跨页功能即可,把复杂逻辑留给人工或单元测试。他们说的都很 reasonable。但我认为端对端测试还是有必要的,一些国外的大公司的端对端测试真的是测试了软件中用户所可能用到的每个功能。这确实是可行,而且有意义的,我们不应该偷懒或者放弃。
面向前端集成的端对端测试 我第一次接触端对端测试是在 Angular 中,于是我看了很多 Angular 中端对端测试的例子,发现很多人面对和我一样问题时,所采取的办法是模拟 HTTP 请求。有人会说,这还算端对端测试吗?这已经不是在完全模拟真实的用户场景了!这种做法只有在后端没有任何 bug 的前提下才是有效的……这些说法都是对的,模拟 HTTP 请求确实是一种 trade off。但作为前端工程师,这样的做法至少能保证我负责的前端系统被测试到了,而且是集成测试,这就够了!后端完全可以另写针对后端的集成测试。当然,模拟 HTTP 请求是在那种迫不得已的情况下才做的,如果你的系统比较简单,比如这些类型:
纯展示型的页面,只是“查找”数据,比较安全。 通过用户操作或在你控制范围内的操作下,可以让数据形成闭环,比如你操作完后,所有的数据恢复如初,就像在沙盒里跑一样 那么就无需模拟 HTTP 了,毕竟我们还是希望能尽量还原真实场景。
端对端测试中模拟 HTTP 请求的几种方法 好了,回归正题。那么如何在端对端测试中模拟 HTTP 请求?有几种方法:
使用代理工具,比如 Charles 代理一些请求,进行模拟。这种方法太麻烦了,不仅要在浏览器上设置代理,还要在 Charles 中配置一堆东西。不推荐! 如果使用 Puppeteer 的话,使用 request.continue 重写一些请求的 url,指向别的链接。你可以自己搭建一个测试服务器进行重写。简单好用,推荐! 如果使用 Puppeteer 的话,使用 request.respond 拦截请求,并直接返回响应结果。简单好用,推荐! 以上三种方法都是可行的,但是后两种更简单。其中,第二种适合那种拥有测试服务器的场景,你只需要对请求链接进行重定向即可。比如原来是 a.com,你将其改为 b.com。但这种方法还是不能非常灵活的模拟每个 case,这时候,第三种方法就更加推荐,你想返回什么都可以直接在函数中写出来。让我们快看看代码实现吧!
真实例子 介绍了背景和方法,我们来看下真实的例子!例子代码在这里:
https://github.com/lewis617/fe-test/tree/master/puppeteer-demo/mock-demo
先说下运行方法:将整个项目 clone 下来后在根目录(不是 mock-demo 这个目录哦)执行以下命令开启服务。
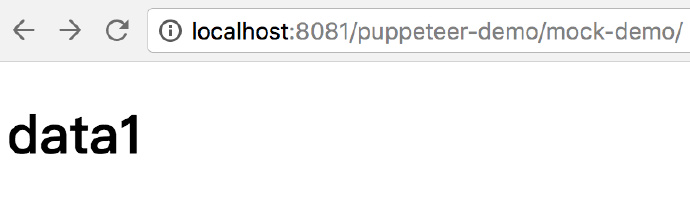
然后就可以在 http://localhost:8081/puppeteer-demo/mock-demo,看到程序了。
这个程序的功能是这样的:
1,在一个简单的 HTML 页面中进行 data1.json 这个文件的请求,并将 JSON 文件中的 name 字段的值显示在 h1 标签中。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" > <meta name ="viewport" content ="width=device-width, initial-scale=1.0" > <meta http-equiv ="X-UA-Compatible" content ="ie=edge" > <title > Document</title > </head > <body > </body > <script > fetch ('http://localhost:8081/puppeteer-demo/mock-demo/data1.json' ) .then (res =>json ()) .then (json =>document .body .innerHTML = `<h1>${json.name} </h1>` ) </script > </html >
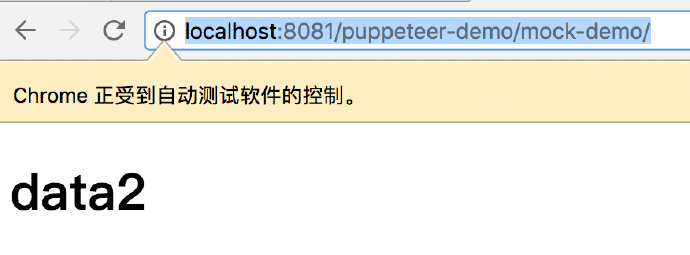
2,我们要做的是,运行 puppeteer,打开页面,并进行请求劫持,将 data1.json 的数据换成 data2.json 的数据。
另开一个终端,执行这些命令:
1 2 3 yarn npm test -- mock-demo
然后就会发现 Puppeteer 中显示的数据是 data2。
我们看下测试脚本是如何进行拦截重写的:
1 2 3 4 5 6 7 8 9 10 11 await page.setRequestInterception (true );page.on ('request' , request => if (request.url .endsWith ('data1.json' )) { request.continue ({ url : 'http://localhost:8081/puppeteer-demo/mock-demo/data2.json' }); } else { request.continue (); } });
上述代码,先设置可以进行请求拦截:await page.setRequestInterception(true);。然后在 request 事件中进行 url 改写。另外,还可以换成 request.respond 方法:
1 2 3 4 5 6 7 8 9 10 11 await page.setRequestInterception (true );page.on ('request' , request => if (request.url .endsWith ('data1.json' )) { request.respond ({ body : JSON .stringify ({ name : 'data2' }) }) } else { request.continue (); } });
就是这么简单。这太好用了!我们甚至可以在日常开发中也使用 Puppeteer 来模拟请求,不需要等待后端的工作。
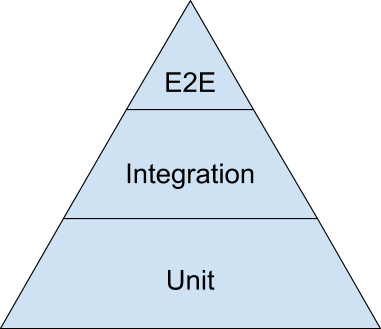
测试金字塔 最后再聊一下端对端测试和单元测试的比例问题。谷歌的测试团队曾经提出过一个测试金字塔的概念 。大概就是单元测试应该最多,然后是集成测试(部分单元之间的集成,不像端对端那样完全黑盒),最少的应该是端对端测试:
为何会这样呢?因为他们认为端对端测试不能像单元测试那样快速的定位问题所在,端对端测试所发现的问题,可能存在系统中的任何位置,但单元测试的反馈定位就更加直接准确。另外,单元测试写起来更加简单快速,而端对端测试则需要整个系统部署好之后才能测试,这样比较慢,毕竟有时候开发周期还是很长的,人家开发一周前写完的代码,你现在才开始测试,有点拖后腿。以上说法非常有道理,我也认为单元测试非常好,但是端对端测试也是有意义的,它可以检测出所有单元连接后的问题,这些问题只能通过端对端测试才能测出来。所以,两者都要写,不要怕麻烦,后期的收益是很大的!
更多测试文章: http://www.liuyiqi.cn/tags/%E6%B5%8B%E8%AF%95/
]]>